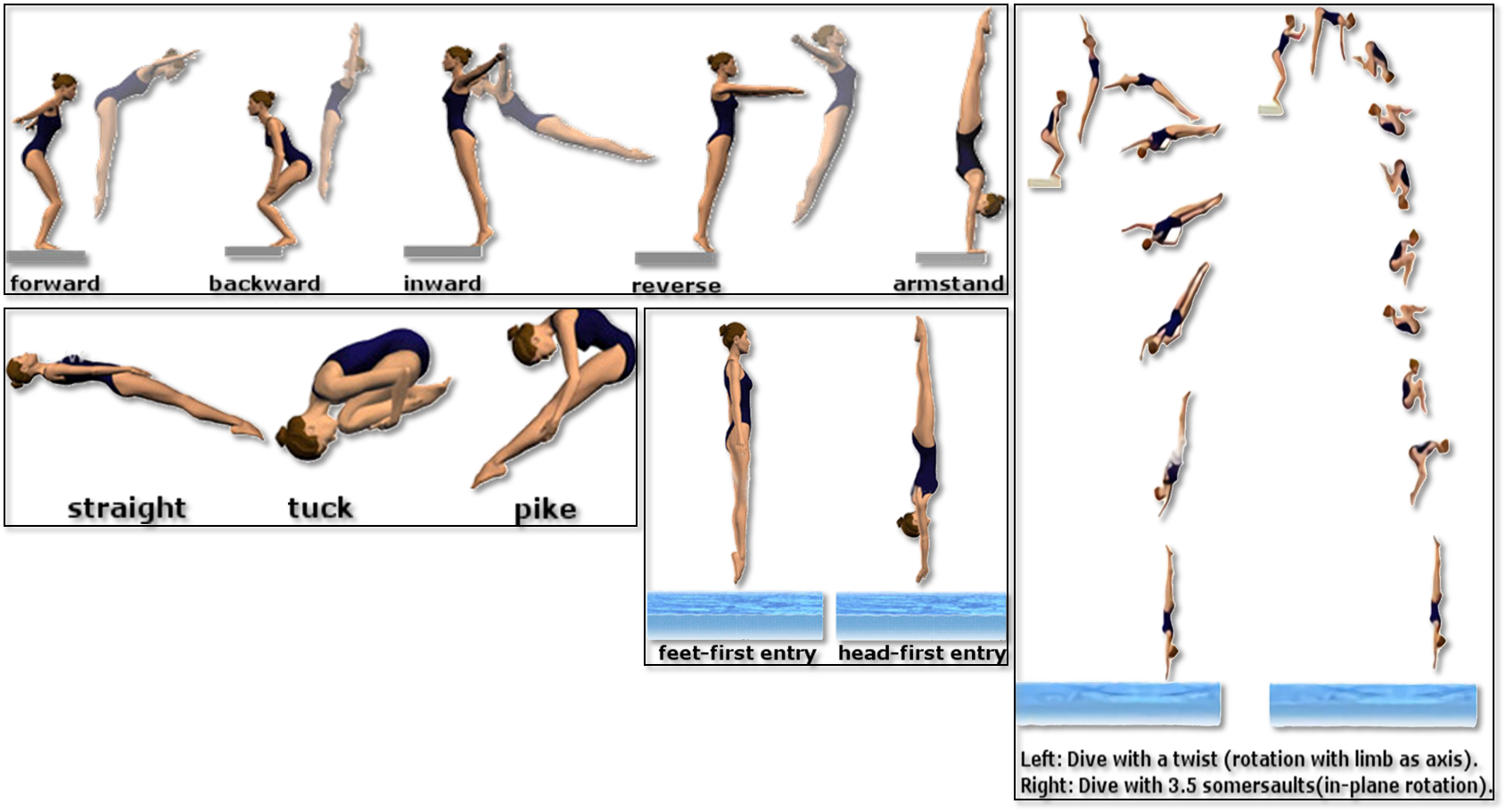
Playground : https://donghuna.com/inference-endpoints/dive-sequence-classification.html
Model : https://huggingface.co/donghuna/timesformer-base-finetuned-k400-diving48
Endpoint : https://ui.endpoints.huggingface.co/donghuna/endpoints/timesformer-base-finetuned-k-wks
Github : https://github.com/donghuna/Dive-sequence-classification/blob/main/Training.ipynb
Dataset : http://www.svcl.ucsd.edu/projects/resound/dataset.html
Introduction
This project aims to develop a model that can classify different diving techniques from video inputs. The motivation behind this project stems from a personal interest in diving and the desire to create a tool that can automatically identify the specific techniques used in diving sequences.
Objectives
The primary goal of this model is to analyze diving videos and accurately classify the type of dive performed. Diving techniques vary based on several factors, such as the diver’s initial position, the direction of the dive, body posture, and the number of rotations. By understanding these factors, the model can categorize dives into their respective classes.
Dataset
The labels for this project are based on the dataset provided by the RESOUND Diving Dataset. This dataset includes a wide range of diving techniques categorized into different classes. The labels encompass various cases such as:
- Initial position (facing forward or backward)
- Direction of the dive (forward or backward)
- Body posture (Straight(A), Tucked(B), Pike(C))
- Number of rotations
- Number of twists
Database Characteristics
The diving videos used for training and evaluation come from the RESOUND dataset. Key characteristics of this database include:
- Number of Videos: A substantial number of videos covering different diving techniques. (Training dataset : 15027, Test dataset : 1970)
- Resolution: Videos are provided in high resolution to capture detailed movements.
- Duration: Each video clip is of sufficient length to encompass the entire dive from takeoff to entry into the water.
Label
The dive ID is determined based on the following factors: Takeoff, Somersault, Twist, and Flight Position
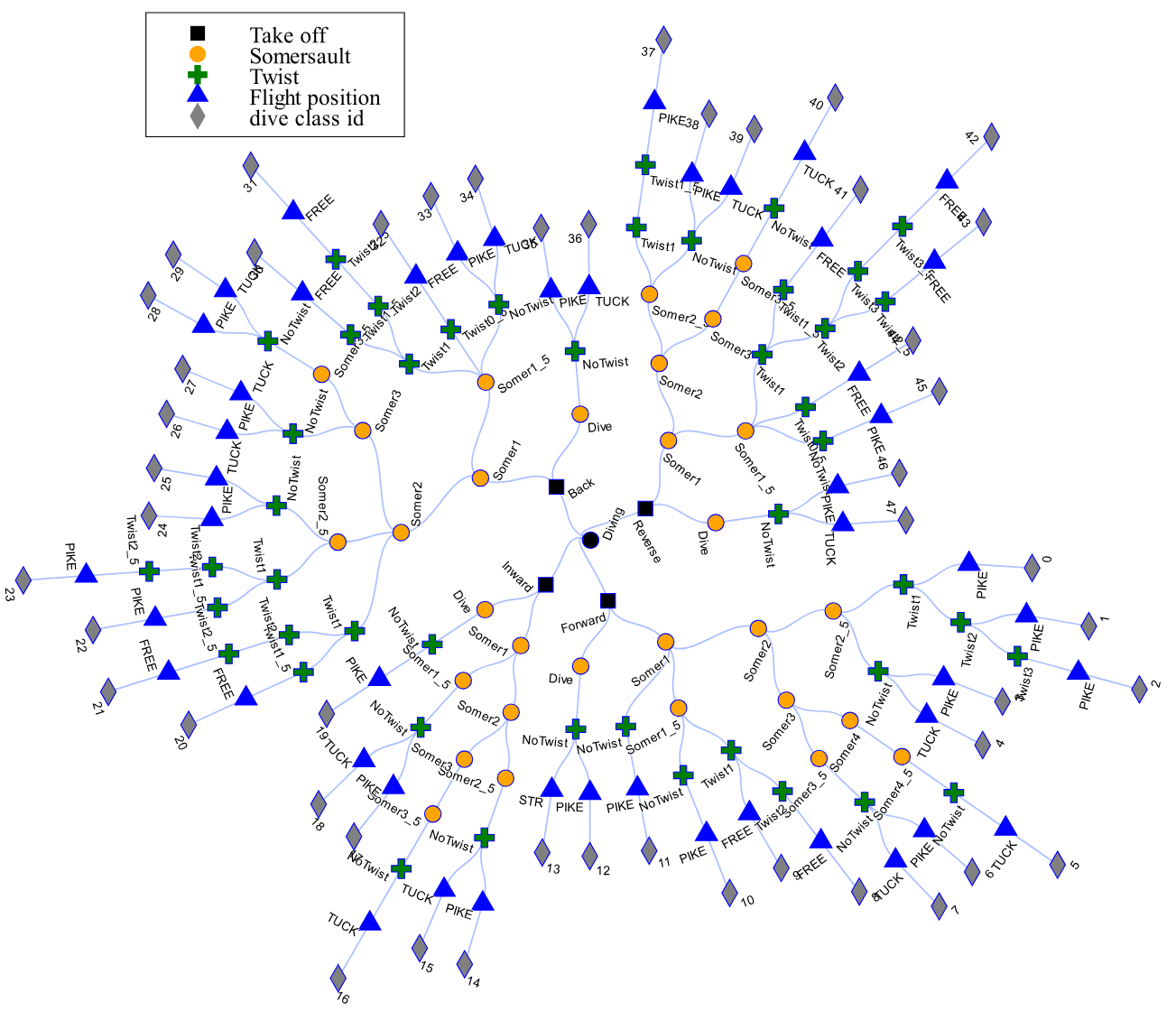
| ID | Take off | Somersault | Twist | Flight position | Dive numbers | Label |
|---|---|---|---|---|---|---|
| 0 | Forward | 2.5 | 1 | PIKE | 5152B | 21 |
| 1 | Forward | 2.5 | 2 | PIKE | 5154B | 22 |
| 2 | Forward | 2.5 | 3 | PIKE | 5156B | 23 |
| 3 | Forward | 2.5 | 0 | PIKE | 105B | 24 |
| 4 | Forward | 2.5 | 0 | TUCK | 105C | 25 |
| 5 | Forward | 4.5 | 0 | TUCK | 109C | 28 |
| 6 | Forward | 3.5 | 0 | PIKE | 107B | 26 |
| 7 | Forward | 3.5 | 0 | TUCK | 107C | 27 |
| 8 | Forward | 1.5 | 2 | FREE | 5134D | 18 |
| 9 | Forward | 1.5 | 1 | FREE | 5132D | 17 |
| 10 | Forward | 1.5 | 0 | PIKE | 103B | 19 |
| 11 | Forward | 1 | 0 | PIKE | 102B | 20 |
| 12 | Forward | Dive | 0 | PIKE | 101B | 29 |
| 13 | Forward | Dive | 0 | STR | 101A | 30 |
| 14 | Inward | 2.5 | 0 | PIKE | 405B | 33 |
| 15 | Inward | 2.5 | 0 | TUCK | 405C | 34 |
| 16 | Inward | 3.5 | 0 | TUCK | 407C | 35 |
| 17 | Inward | 1.5 | 0 | PIKE | 403B | 31 |
| 18 | Inward | 1.5 | 0 | TUCK | 403C | 32 |
| 19 | Inward | Dive | 0 | PIKE | 401B | 36 |
| 20 | Back | 2 | 1.5 | FREE | 5243D | 9 |
| 21 | Back | 2 | 2.5 | FREE | 5245D | 10 |
| 22 | Back | 2.5 | 1.5 | PIKE | 5253B | 5 |
| 23 | Back | 2.5 | 2.5 | PIKE | 5255B | 6 |
| 24 | Back | 2.5 | 0 | PIKE | 205B | 7 |
| 25 | Back | 2.5 | 0 | TUCK | 205C | 8 |
| 26 | Back | 3 | 0 | PIKE | 206B | 13 |
| 27 | Back | 3 | 0 | TUCK | 206C | 14 |
| 28 | Back | 3.5 | 0 | PIKE | 207B | 11 |
| 29 | Back | 3.5 | 0 | TUCK | 207C | 12 |
| 30 | Back | 1.5 | 1.5 | FREE | 5233D | 1 |
| 31 | Back | 1.5 | 2.5 | FREE | 5235D | 2 |
| 32 | Back | 1.5 | 0.5 | FREE | 5231D | 0 |
| 33 | Back | 1.5 | 0 | PIKE | 203B | 3 |
| 34 | Back | 1.5 | 0 | TUCK | 203C | 4 |
| 35 | Back | Dive | 0 | PIKE | 201B | 15 |
| 36 | Back | Dive | 0 | TUCK | 201C | 16 |
| 37 | Reverse | 2.5 | 1.5 | PIKE | 5353B | 42 |
| 38 | Reverse | 2.5 | 0 | PIKE | 305B | 43 |
| 39 | Reverse | 2.5 | 0 | TUCK | 305C | 44 |
| 40 | Reverse | 3.5 | 0 | TUCK | 307C | 45 |
| 41 | Reverse | 1.5 | 1.5 | FREE | 5333D | 38 |
| 42 | Reverse | 1.5 | 3.5 | FREE | 5337D | 40 |
| 43 | Reverse | 1.5 | 2.5 | FREE | 5335D | 39 |
| 44 | Reverse | 1.5 | 0.5 | FREE | 5331D | 37 |
| 45 | Reverse | 1.5 | 0 | PIKE | 303B | 41 |
| 46 | Reverse | Dive | 0 | PIKE | 301B | 46 |
| 47 | Reverse | Dive | 0 | TUCK | 301C | 47 |
How to Identify Dive Numbers
Dives are described by their full name (e.g. reverse 3 1/2 somersault with 1/2 twist) or by their numerical identification (e.g. 5371D), or “dive number.”
Specific dive numbers are not random. They are created by using these guidelines:
-
All dives are identified by three or four digits and one letter. Twisting dives utilize four numerical digits, while all other dives use three.
-
The first digit indicates the dive’s group: 1 = forward, 2 = back, 3 = reverse, 4 = inward, 5 = twisting, 6 = armstand.
-
In front, back, reverse, and inward dives, a ‘1’ as the second digit indicates a flying action. A ‘0’ indicates none. In twisting and armstand dives, the second digit indicates the dive’s group (forward, back, reverse).
-
The third digit indicates the number of half somersaults.
-
The fourth digit, if applicable, indicates the number of half twists.
-
The letter indicates body position: A = straight, B = pike, C = tuck, D = free.
Examples:
107B = Forward dive with 3 1/2 somersaults in a pike position
305C = Reverse dive with 2 1/2 somersaults in a tuck position
5253B = Back dive with 2 1/2 somersaults and 1 1/2 twists in a pike position
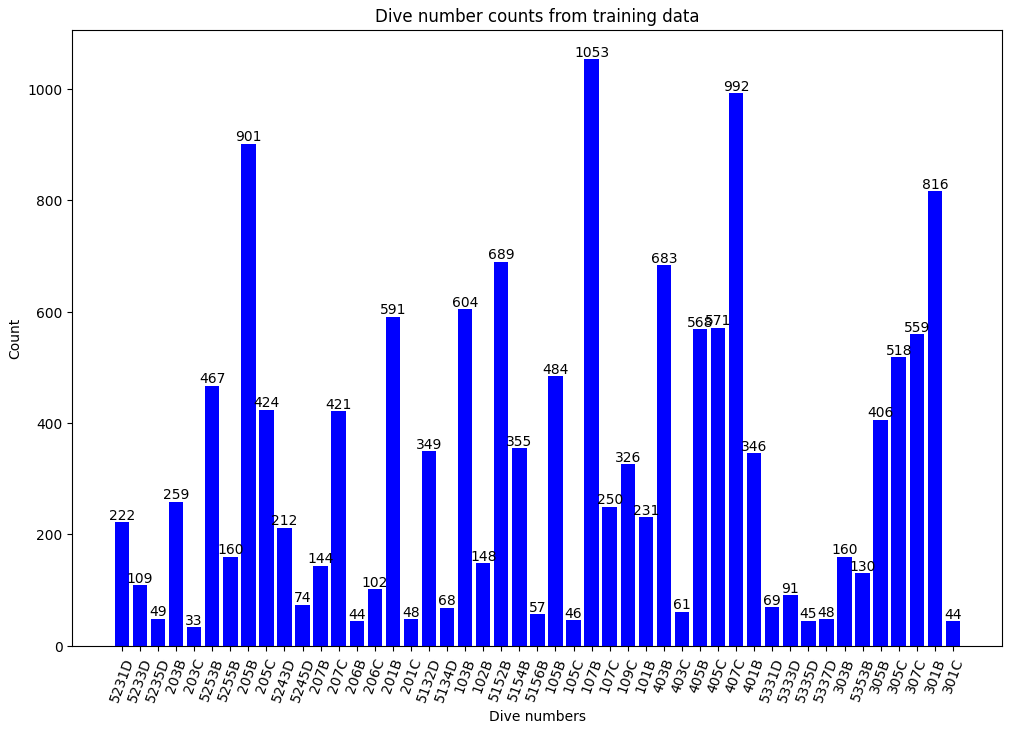
Dive number counts from training data
Dataloader Configuration
To effectively train the model, the dataloader is configured with specific preprocessing steps:
- Image Preprocessing: Videos are resized and normalized to ensure consistency across the dataset. (224 x 224)
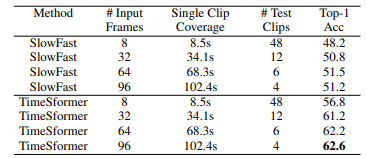
- Frame Extraction: A fixed number of frames are extracted from each video to represent the sequence. As shown in the table below, increasing the number of input frames results in higher accuracy, but due to resource constraints, 24 frames were used.
- Batch Size: The batch size is set to optimize memory usage and training time. Due to memory constraints, each batch included 2 videos.
- Shuffling: Data shuffling is implemented to ensure a diverse mix of training samples in each batch. Random shuffling was applied.
Transformer Model Explanation
effectiveness in video understanding. Here’s a brief overview of its components:
- Self-Attention Mechanism: Timesformer uses self-attention to capture dependencies between different frames in a video. This allows the model to understand the temporal dynamics of the diving sequence.

- Positional Encoding: To maintain the sequential information of frames, positional encodings are added to the frame embeddings.

- Layers and Heads: The model consists of multiple layers of attention heads that allow it to focus on different parts of the sequence simultaneously.
- Loss Function: Cross-entropy loss is used for classification, optimizing the model to predict the correct dive class.
- Optimization: Adam optimizer with a carefully tuned learning rate is used to train the model.
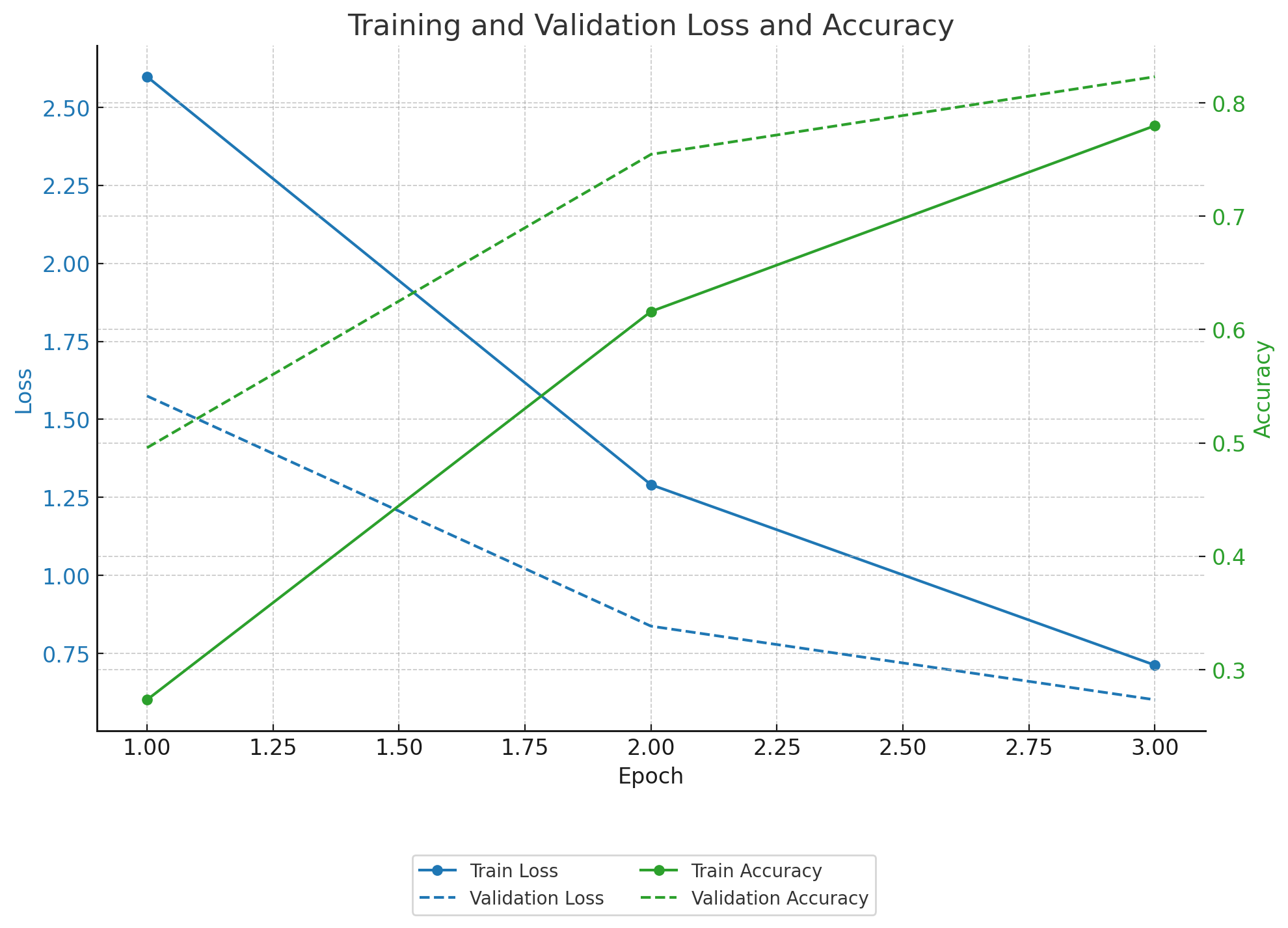
Training and Results
- Accuracy: The model achieves high accuracy in classifying various diving techniques.
Test Accuracy: 0.5208
- Loss: The training and validation loss curves indicate good convergence. Performing a few more epochs can potentially improve accuracy.
Epoch [1/3], Loss: 2.5981627, Train Accuracy: 0.2734
Validation Loss: 1.5747785, Validation Accuracy: 0.4957
Epoch [2/3], Loss: 1.2904986, Train Accuracy: 0.6159
Validation Loss: 0.8370838, Validation Accuracy: 0.7545
Epoch [3/3], Loss: 0.7121527, Train Accuracy: 0.7798
Validation Loss: 0.6011413, Validation Accuracy: 0.8230
- Class-wise Performance (Confusion Matrix):
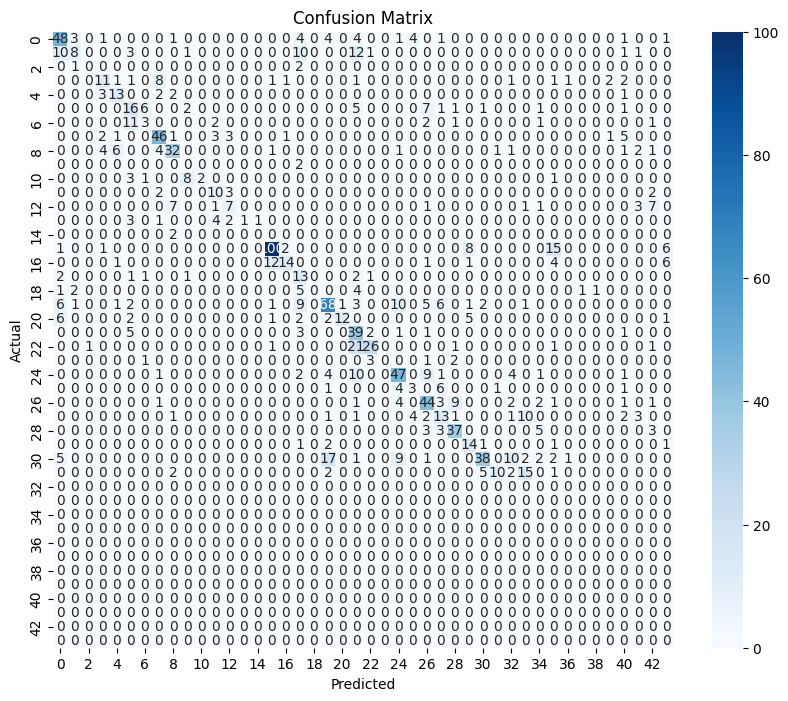
Labels with limited training data may have lower prediction accuracy.
Architecture

Conclusion
The developed Timesformer-based model successfully classifies diving techniques from video inputs. This project demonstrates the potential of Transformer models in video classification tasks and provides a foundation for further development and applications in sports analysis and other fields. Naturally, poses that have not been trained cannot be classified by the model, such as basic positions. However, with additional training, more types of dives can be included, and classification accuracy can be improved by training with videos from specific angles.
Training code
https://github.com/donghuna/AI-Expert/blob/main/timesformer/TimeSformer-huggingface-example.ipynb
import json
import os
import random
from ftplib import FTP
import io
import numpy as np
import av
import torch
from torch.utils.data import Dataset, DataLoader, random_split
from torchvision.utils import save_image
from torchvision import transforms
from transformers import TimesformerForVideoClassification, get_linear_schedule_with_warmup, AdamW
from tqdm import tqdm
# FTP 서버 정보
ftp_server = ""
ftp_port =
ftp_user = ""
ftp_password = ""
folder_path = ""
# FTP 연결 설정
ftp = FTP()
ftp.connect(ftp_server, ftp_port)
ftp.login(user=ftp_user, passwd=ftp_password)
ftp.set_pasv(True)
# 동영상 데이터셋 경로
train_json_path = "Diving48_V2_train.json"
test_json_path = "Diving48_V2_test.json"
with open(train_json_path, 'wb') as local_file:
ftp.retrbinary(f'RETR {"homes/donghuna/database/Diving48_rgb/Diving48_V2_train.json"}', local_file.write)
with open(test_json_path, 'wb') as local_file:
ftp.retrbinary(f'RETR {"homes/donghuna/database/Diving48_rgb/Diving48_V2_test.json"}', local_file.write)
# 동영상 데이터를 읽어오기 위한 함수
def read_video_from_ftp(ftp, file_path, start_frame, end_frame):
video_data = io.BytesIO()
ftp.retrbinary(f'RETR {file_path}', video_data.write)
video_data.seek(0)
container = av.open(video_data, format='mp4')
frames = []
for i, frame in enumerate(container.decode(video=0)):
if i > end_frame:
break
if i >= start_frame:
frame_np = frame.to_ndarray(format="rgb24")
frames.append(frame_np.astype(np.uint8))
return np.stack(frames, axis=0)
def sample_frames(frames, num_frames):
total_frames = len(frames)
sampled_frames = list(frames)
if total_frames <= num_frames:
# sampled_frames = frames
if total_frames < num_frames:
padding = [np.zeros_like(frames[0]) for _ in range(num_frames - total_frames)]
sampled_frames.extend(padding)
# sampled_frames = np.concatenate([sampled_frames, padding], axis=0)
else:
indices = np.linspace(0, total_frames - 1, num=num_frames, dtype=int)
sampled_frames = [frames[i] for i in indices]
return np.array(sampled_frames)
# 변환 함수 정의
def pad_and_resize(frames, target_size):
transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize(target_size),
transforms.ToTensor()
])
processed_frames = [transform(frame) for frame in frames]
return torch.stack(processed_frames)
def read_and_process_video(ftp, file_path, start_frame, end_frame, target_size, num_frames):
frames = read_video_from_ftp(ftp, file_path, start_frame, end_frame)
frames = sample_frames(frames, num_frames=num_frames)
processed_frames = pad_and_resize(frames, target_size=target_size)
processed_frames = processed_frames.permute(1, 0, 2, 3) # (T, C, H, W) -> (C, T, H, W)
return processed_frames
# Diving48 데이터셋 클래스 정의
class Diving48Dataset(Dataset):
def __init__(self, json_path, ftp, folder_path, target_size=(224, 224), num_frames=24):
with open(json_path, 'r') as f:
self.data = json.load(f)
self.ftp = ftp
self.folder_path = folder_path
self.target_size = target_size
self.num_frames = num_frames
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
vid_info = self.data[idx]
vid_name = vid_info['vid_name']
label = vid_info['label']
start_frame = vid_info['start_frame']
end_frame = vid_info['end_frame']
file_path = os.path.join(self.folder_path, f"{vid_name}.mp4")
video = read_and_process_video(self.ftp, file_path, start_frame, end_frame, target_size=self.target_size, num_frames=self.num_frames)
return video, label
# 데이터셋 및 데이터로더 생성
full_train_dataset = Diving48Dataset(train_json_path, ftp, folder_path)
# Train-validation split
train_size = int(0.8 * len(full_train_dataset))
val_size = len(full_train_dataset) - train_size
train_dataset, val_dataset = random_split(full_train_dataset, [train_size, val_size])
test_dataset = Diving48Dataset(test_json_path, ftp, folder_path)
def collate_fn(batch):
videos, labels = zip(*batch)
videos = torch.stack(videos)
videos = videos.permute(0, 2, 1, 3, 4) # (B, T, C, H, W) -> (B, C, T, H, W)
labels = torch.tensor(labels)
return videos, labels
train_loader = DataLoader(train_dataset, batch_size=2, shuffle=True, collate_fn=collate_fn)
val_loader = DataLoader(val_dataset, batch_size=2, shuffle=False, collate_fn=collate_fn)
test_loader = DataLoader(test_dataset, batch_size=2, shuffle=False, collate_fn=collate_fn)
from google.colab import drive
drive.mount('/content/drive')
# # 모델 저장
# # torch.save(model.state_dict(), '/content/drive/MyDrive/timesformer_weight/model_epoch_{epoch+1}.pt')
# # 변환된 동영상 저장 함수
# def save_transformed_video(video_tensor, filename):
# # (C, T, H, W) -> (T, C, H, W)
# # video_tensor = video_tensor.permute(1, 0, 2, 3)
# for i, frame in enumerate(video_tensor):
# save_image(frame, f"{filename}_frame_{i}.png")
# # 변환된 동영상 저장 (테스트 데이터셋의 첫 번째 비디오)
# video, label = train_dataset[1]
# save_transformed_video(video, '/content/drive/MyDrive/transfomed_video/transformed_video')
# ftp.quit()
# 모델 로드
model = TimesformerForVideoClassification.from_pretrained("facebook/timesformer-base-finetuned-k400")
model.load_state_dict(torch.load("/content/drive/MyDrive/timesformer_weight/model_epoch_1.pt"))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
optimizer = AdamW(model.parameters(), lr=5e-5)
num_epochs = 5
num_training_steps = num_epochs * len(train_loader)
lr_scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=0, num_training_steps=num_training_steps)
loss_fn = torch.nn.CrossEntropyLoss()
for epoch in range(num_epochs):
model.train()
total_loss = 0
correct_train = 0
total_train = 0
train_progress = tqdm(train_loader, desc=f"Epoch {epoch+1}/{num_epochs}")
for batch in train_progress:
videos, labels = batch
videos = videos.to(device)
labels = labels.to(device)
outputs = model(videos)
loss = loss_fn(outputs.logits, labels)
total_loss += loss.item()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
_, predicted = torch.max(outputs.logits, 1)
correct_train += (predicted == labels).sum().item()
total_train += labels.size(0)
avg_loss = total_loss / len(train_loader)
train_accuracy = correct_train / total_train
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {avg_loss:.7f}, Train Accuracy: {train_accuracy:.4f}")
# validation
model.eval()
correct_val = 0
total_val = 0
val_loss = 0
# validate_dim_lengthloop_time = 0
val_progress = tqdm(val_loader, desc=f"Validation {epoch+1}/{num_epochs}")
with torch.no_grad():
for batch in val_progress:
videos, labels = batch
videos = videos.to(device)
labels = labels.to(device)
outputs = model(videos)
loss = loss_fn(outputs.logits, labels)
val_loss += loss.item()
_, predicted = torch.max(outputs.logits, 1)
correct_val += (predicted == labels).sum().item()
total_val += labels.size(0)
# validate_dim_lengthloop_time += 1
# if validate_dim_lengthloop_time % 10 == 0:
# break
val_loss /= len(val_loader)
val_accuracy = correct_val / total_val
print(f"Validation Loss: {val_loss:.7f}, Validation Accuracy: {val_accuracy:.4f}")
# 모델 파라미터 저장
torch.save(model.state_dict(), f'/content/drive/MyDrive/timesformer_weight/model_epoch_{epoch+1}.pt')
model.push_to_hub("donghuna/timesformer-base-finetuned-k400-diving48")
# 평가 루프
model.eval()
total_correct = 0
total_samples = 0
test_progress = tqdm(test_loader, desc="Testing")
with torch.no_grad():
for batch in test_progress:
videos, labels = batch
videos = videos.to(device)
labels = labels.to(device)
outputs = model(videos)
_, predicted = torch.max(outputs.logits, 1)
total_correct += (predicted == labels).sum().item()
total_samples += labels.size(0)
accuracy = total_correct / total_samples
print(f"Test Accuracy: {accuracy:.4f}")
# 연결 종료
ftp.quit()
101A, 101B, 102B, 103B, 105B, 105C, 107B, 107C, 109C, 201B, 201C, 203B, 203C, 205B, 205C, 206B, 206C, 207B, 207C, 301B, 301C, 303B, 305B, 305C, 307C, 401B, 403B, 403C, 405B, 405C, 407C, 5132D, 5134D, 5152B, 5154B, 5156B, 5231D, 5233D, 5235D, 5243D, 5245D, 5253B, 5255B, 5331D, 5333D, 5335D, 5337D, 5353B