Model : https://huggingface.co/donghuna/llama-plan-1B
Dataset : https://huggingface.co/datasets/donghuna/StaQC-plan
Github : https://github.com/donghuna/PromptGenerate
배경
LLM의 지속적인 발전
최신 대규모 언어 모델(LLM)은 점차 모델 크기를 늘리며 성능을 향상
OpenAI, Meta 등에서 최신 고성능 LLM들이 지속적이고 짧은 주기로 릴리즈
사내 제한
보안 문제로 인해 On-premise 방식의 네이버 HCX와 SR의 GAUSS모델을 사용
해당 모델들은 외부 최신 LLM 대비 성능 뒤처짐
사내 모델의 문제점
내부 모델의 성능 한계로 임직원 불만 증가
외부 최신 모델과의 성능 격차로 인해 지속적인 비교와 높은 성능 요구 발생
프로젝트 목표
제한된 성능의 모델로도 더 나은 결과를 도출하기 위해 최적화된 프롬프트 생성 모델 구현
효율적인 프롬프트 설계를 통해 내부 모델의 Code generation 품질을 향상시키는 방안 개발
실제 사용성을 고려하여, 모델 크기를 과도하게 키우지 않고, 양자화를 적용하여 응답 속도에 최적화된 모델로 구현
코드 생성 성능 향상을 위한 방법
기존 방식
현재는 사용자 프롬프트를 전처리 없이, 그대로 LLM에 입력하여 코드 생성을 수행
프롬프트에 구체적인 정보가 부족, 사용자 의도 반영이 되지 않아 코드 품질이 낮아질 가능성 존재
LLM이 명확한 컨텍스트 없이 작업을 수행하여 결과물의 일관성이 떨어짐
제안 방식
User prompt를 기반으로 유사 질문과 코드를 검색, 코드 생성을 위한 플랜 생성
Enhanced prompt를 통해 In-Context learning(ICL) 효과를 극대화 하여 모델의 코드 작성 이해도와 품질 향상
제한된 환경에서도 효율적이고 신뢰성 높은 코드 생성 기대
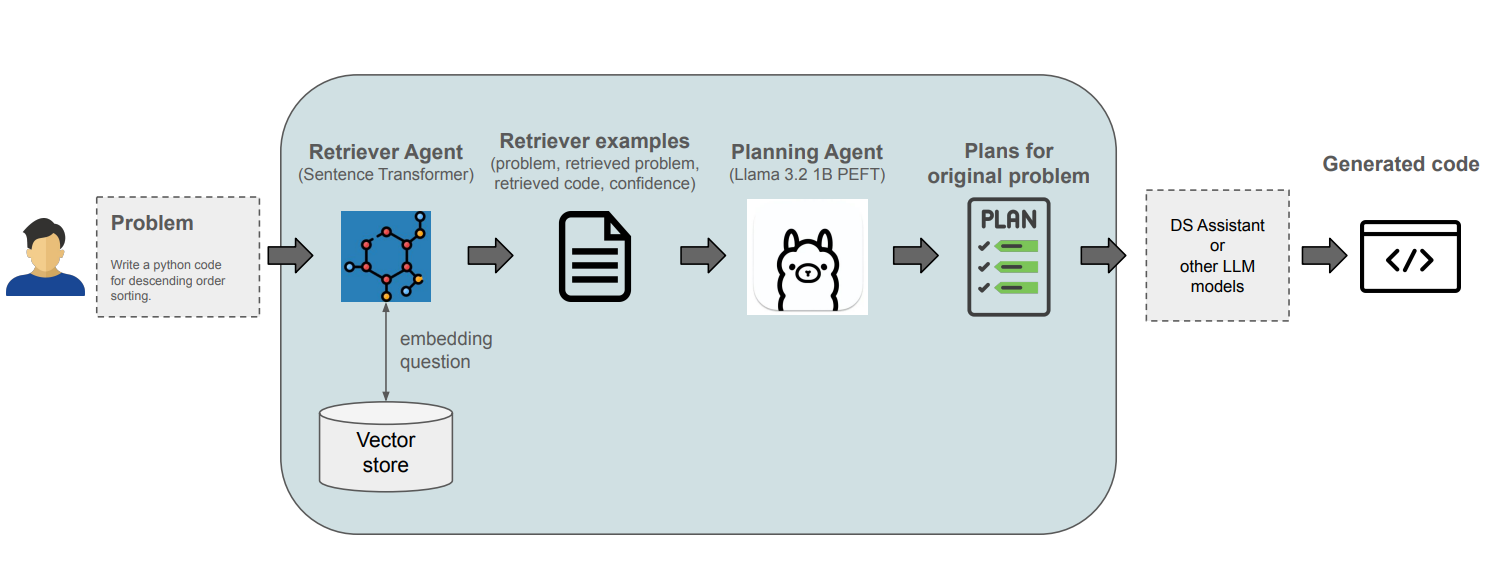
전체 파이프라인 구조
Retriever Agent (RAG 적용)
Retrieval augmented generation 기법을 활용, 사용자 프롬프트와 유사한 질문 및 관련 코드 예제를 검색
검색된 예제는 문제 해결에 필요한 힌트와 맥락을 제공 -> 프롬프트의 정보량을 보강
Planning Agent (PEFT 적용)
검색된 유사 질문을 참고하여 사용자 문제를 해결하기 위한 단계적 Plan 작성
Parameter Efficient fine-tuning 기법으로 경량화된 미세 조정을 수행, 제한된 환경에서도 높은 성능의 plan 생성
QLoRA를 통해 메모리 사용량 감소 및 응답 속도 최적화를 실현하면서도 높은 성능 유지
Retriever Agent
Embedding Model
Sentence Transformer (paraphrase-MiniLM-L6-v2)를 사용하여 사용자 prompt를 vector로 변환
Encoder 기반 모델로 텍스트의 의미적 유사도를 효과적으로 학습
Dataset
StackOverflow의 python 언어와 관련된 question과 code snippet 데이터
Vector store
FAISS(Facebook AI Similarity Search)를 사용하여 고성능 vector indexing 및 search 수행
StackOverflow에서 수집한 question 데이터를 vector화 하여 indexing 처리
Planning Agent
Training
Data augmenation : Stackoverflow dataset을 활용하여 Similar question, confidence score, plan 생성
Quantization + PEFT :
QLoRA 기법 적용 (Trainable params 0.883%)
Llama 3.2 1B 모델을 16-bit에서 4-bit로 양자화 (Quantization)
메모리 효율성을 극대화 하면서 성능 유지
Training method :
Input : Question + Similar question + code + confidence + plan
Tokenization : Input_ids + labels
Model Training : Teacher Forcing 방식으로 plan 학습
기대 효과
Strengths
기존 code Geneartion LLM의 성능 보완 :
Code generation 모델의 성능이 부족한 제한된 환경에서도 Planning agent와 Retriever agent를 통해 높은 품질의 코드 생성 가능
다양한 Task로 확장 가능 :
본 파이프라인은 code generation뿐 아니라, 다양한 Task에 적용하여 성능을 높일 수 있음
예: 문서용약, 데이터 분석 플로우 생성 등
효율적인 자원 활용 :
QLoRA 기반 양자화와 Llama 3.2 1B 모델 사용으로, 학습과 추론에 필요한 자원과 시간이 크게 절감
대규모 모델 대비 메모리 사용량 감소 및 환경 요구 사항이 낮음
Limitations
Plan에 대한 높은 의존성 :
현재는 plan이 매우 구체적으로 작성되어 plan 품질에 따라 전체 성능이 크게 좌우됨
이를 더 추상적으로 일반화 할 필요
전체 추론 시간 증가 (End-to-End Latency) :
프롬프트 입력부터 최종 응답까지의 지연시간이, 기존 방식 대비 증가
LLM을 포함한 각각의 추가적인 agent 과정으로 인해 응답 속도가 느려질 가능성